지난 글에서는 one-hot을 이용해서 단어와 문서를 vectorization하고 bow를 만들었습니다. 하지만 이런 희소 표현으로 vectorization을 하게되면 매우 high-demensional feature space를 갖게 되고 overfitting의 위험이 있습니다. 또한 one-hot vector는 단어간의 의미간 유사도를 계산할 수 없습니다. 모든 단어가 다 같은 거리를 같게 됩니다.
Word Embedding
이를 극복하기 위해 고안된 방법이 Word Embedding입니다.
Word Embedding이란 단어를 주어진 차원의 실수 벡터로 표현하는 dense representation(밀집 표현) 방법입니다. 차원을 제한하기 때문에 단어간의 거리가 서로 달라질 수 밖에 없고, 따라서 단어간의 관계(거리)가 생깁니다! 따라서 단어의 의미(semantic)을 이용해서 유사한 단어를 보다 가깝게 mappting할 수 있습니다. 예를 들어, dog와 puppy의 거리를 dog와 cake의 거리보다 더 가깝게 나타낼 수 있겠습니다.
Word Embedding을 하기 위한 방법으로는 Word2Vec, GloVe, fastText, kor2vec 등이 있습니다. 사실 저도 모두 다 처음 들어보는 것이고, 다뤄본 적도 없기 때문에 잘 모릅니다. 오늘은 가장 대표적인 방법인 Word2Vec방법을 이용해서 Word Embedding을 해보도록 하겠습니다.
Word2Vec
Word2Vec은 단순한 형태의 신경망을 이용해서 주어진 단어와 관계가 있는 단어를 학습하여 단어를 일정한 실수 벡터로 projection하는 방법입니다. 여기서 단순한 형태의 신경망이란, activation function이 없는 2-layer neural network를 의미하고, 관계가 있는 단어는 "가까이 있는 단어"로 가정합니다.
Word2Vec의 학습 방식에는 CBOW(Continuous Bag of Words)와 Skip-gram 두 가지 방식이 있습니다.
CBOW(Continuous Bag of Words)는 주변 단어들로 중심 단어를 예측하는 방법이고, Skip-gram 중심단어로 주변 단어들을 예측하는 방법입니다.
예를 들어, "The fat cat sat on the mat"라는 문장에서 fat, cat, on, the(context word)로 sat(center word)를 예측하면 CBOW 방법이고, sat(center word)이 주어졌을 때, fat, cat, on, the(context word)를 예측하면 Skip-gram 방법입니다.
먼저 CBOW의 신경망이 어떻게 이루어져있는지 보겠습니다. 우선, 사용자가 몇개의 주변 단어들을 볼 것인지 결정해야 합니다. 이것을 윈도우라고 부르는데, 예를 들어 "The fat cat sat on the mat"라는 문장에서 중심 단어 앞 뒤로 1개씩만 본다면 윈도우는 1이 되고, 이를 3개씩 뭉쳐서 본다는 의미로 3-gram이라고 부르기도 합니다.
즉, ☐ The fat, The fat cat, fat cat sat, cat sat on, on the mat, the mat ☐ 이렇게요.

위의 그림에서는 윈도우를 2로 정하여 sat의 앞뒤로 2개씩 총 4개의 단어들이 one-hot vector의 형태로 input layer로 들어가는 것을 볼 수 있습니다. 앞서 이야기 했듯이 Word2Vec은 단순한 형태의 신경망으로 단 하나의 hidden layer만을 사용하기 때문에 activation function이 존재하지 않아 hidden layer가 단순히 lookup table로서 연산만을 담당하게 됩니다. 따라서 우리는 CBOW에서 hidden layer를 projection layer라고 부르기도 합니다.
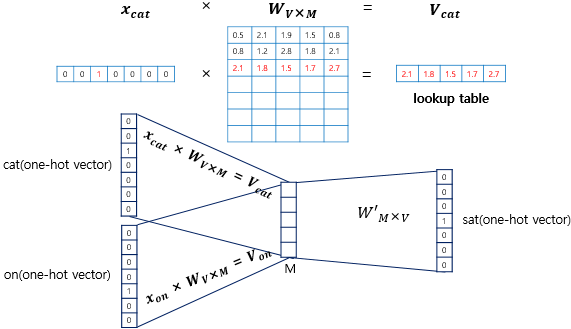
input layer로 단어들의 one-hot vector가 들어오기 때문에 가중치 W에서 들어온 단어에 해당하는 벡터만 pick하여 내보내게 됩니다.(projection)
위 그림에서는 projection layer의 크기를 5로 설정하였습니다. 따라서 CBOW를 수행한 각 단어의 embedding vetor의 크기(차원)은 5가 됩니다. 이후에 projection layer와 ouput layer 사이의 가중치 행렬과 곱하여서 다시 one-hot vector의 형태로 output vector가 만들어지게 됩니다.
이 때, input vector의 개수가 2개이므로(3-gram) 가중치 $W$와 곱해져서 벡터 2개가 뽑히는데(lookup) CBOW에서는 이 벡터들의 평균을 내어서 가중치 $W'$와 곱합니다. 그리고 softmax함수를 적용하여 score vector를 만들고 손실함수(여기서는 cross entropy사용)에서 사용합니다. (backpropagation을 수행하면서 $W$와 $W'$을 학습)

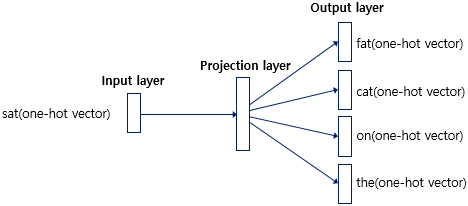
다음으로는 skip-gram의 신경망이 어떻게 구성되어 있는지 보겠습니다. 전반적으로 CBOW와 신경망 구조가 다르지 않습니다. 하지만 skip-gram이 앞서 살펴본 CBOW와 가장 크게 다른 점은 input layer에 벡터가 하나만 들어온다는 것입니다. center word의 one-hot vector만 들어오게됩니다. 따라서 projection layer에서 벡터들의 평균을 구할 필요가 없습니다. 이외의 다른 신경망 구조는 모두 같습니다.
https://github.com/graykode/nlp-tutorial/blob/master/1-2.Word2Vec/Word2Vec-Skipgram(Softmax).py
GitHub - graykode/nlp-tutorial: Natural Language Processing Tutorial for Deep Learning Researchers
Natural Language Processing Tutorial for Deep Learning Researchers - GitHub - graykode/nlp-tutorial: Natural Language Processing Tutorial for Deep Learning Researchers
github.com
skip-gram을 직접 손으로 구현해보는 코드로 graykode님의 코드를 참고해보았습니다.
sentences = ["apple banana fruit", "banana orange fruit", "orange banana fruit",
"dog cat animal", "cat monkey animal", "monkey dog animal"]
word_sequence = ' '.join(sentences).split()
word_list = list(set(' '.join(sentences).split()))
word_dict = {word: idx for idx, word in enumerate(word_list)}
voc_size = len(word_list)
# Make skip gram of one size window
skip_gram = []
for i in range(1, len(word_sequence) - 1):
target = word_dict[word_sequence[i]]
context = [word_dict[word_sequence[i - 1]], word_dict[word_sequence[i + 1]]]
for w in context:
skip_gram.append([target, w])
# skip_gram = {list: 32} [[1, 3], [1, 2], [2, 1], [2, 1], [1, 2],
# [1, 0], [0, 1], [0, 2], [2, 0], [2, 0], [0, 2], [0, 1],
# [1, 0], [1, 2], [2, 1], [2, 7], [7, 2], [7, 4], [4, 7],
# [4, 6], [6, 4], [6, 4], [4, 6], [4, 5], [5, 4], [5, 6],
# [6, 5], [6, 5], [5, 6], [5, 7], [7, 5], [7, 6]]우선 vocaburary와 skip gram을 만듭니다. skip_gram에는 위와 같이 32개의 vocaburary index의 pair가 들어가 있습니다.
다음으로는 Word2Vec 모델을 만들어봅시다.
class Word2Vec(nn.Module):
def __init__(self):
super(Word2Vec, self).__init__()
self.W = nn.Linear(voc_size, embedding_size, bias = False)
self.Wt = nn.Linear(embedding_size, voc_size, bias = False)
def forward(self, x):
# shape of x: [batch_size, voc_size]
hidden_layer = self.W(x) # shape of hidden layer: [batch_size, embedding_size]
output_layer = self.Wt(hidden_layer) # shape of output layer: [batch_size, voc_size]
return (output_layer)projection layer(hidden layer)는 단어장의 크기(batch size)만큼의 input이 들어와서 embedding vector의 size로 나가고, output layer는 embedding vector의 size만큼 들어와서 원래 단어장의 크기로 다시 나갑니다.
이제 training을 해보겠습니다.
def train(model, input_batch, target_batch, loss_func, optimizer):
model.train()
optimizer.zero_grad()
output = model(input_batch)
loss = loss_func(output, target_batch)
loss.backwward()
optimizer.step()
return losstrain() 함수는 기본적으로 작성하였고,
input_batch와 target_batch를 random하게 받아오는 부분은 random_batch()함수를 이용하여 작성하였습니다.
def random_batch():
random_inputs = []
random_labels = []
random_index = np.random.choice(range(len(skip_gram)), batch_size, replace=False)
for i in random_index:
random_inputs.append(np.eye(voc_size)[skip_gram[i][0]]) # target
random_labels.append(skip_gram[i][1]) # context word
random_inputs = torch.tensor(random_inputs, dtype=torch.float32)
random_labels = torch.LongTensor(random_labels)
return random_inputs, random_labels
출력 부분과 전체 코드를 포함한 전체 코드는 다음과 같습니다. (시각화를 위해서 embedding size는 2로 주었습니다.)
# code by Tae Hwan Jung @graykode
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# Define hyperparameters
EPOCH_MAX = 5000
EPOCH_LOG = 1000
RANDOM_SEED = 777
BATCH_SIZE = 2
EMBEDDING_SIZE = 2
OPTIMIZER_PARAMS = {'lr': 0.001}
def random_batch():
random_inputs = []
random_labels = []
random_index = np.random.choice(range(len(skip_gram)), batch_size, replace=False)
for i in random_index:
random_inputs.append(np.eye(voc_size)[skip_gram[i][0]]) # target
random_labels.append(skip_gram[i][1]) # context word
random_inputs = torch.tensor(random_inputs, dtype=torch.float32)
random_labels = torch.LongTensor(random_labels)
return random_inputs, random_labels
# Model
class Word2Vec(nn.Module):
def __init__(self):
super(Word2Vec, self).__init__()
self.W = nn.Linear(voc_size, embedding_size, bias = False)
self.Wt = nn.Linear(embedding_size, voc_size, bias = False)
def forward(self, x):
# shape of x: [batch_size, voc_size]
hidden_layer = self.W(x) # shape of hidden layer: [batch_size, embedding_size]
output_layer = self.Wt(hidden_layer) # shape of output layer: [batch_size, voc_size]
return (output_layer)
def train(model, input_batch, target_batch, loss_func, optimizer):
model.train()
optimizer.zero_grad()
output = model(input_batch)
loss = loss_func(output, target_batch)
loss.backward()
optimizer.step()
return loss
if __name__ == '__main__':
batch_size = BATCH_SIZE # mini-batch size
embedding_size = EMBEDDING_SIZE # embedding size
torch.manual_seed(RANDOM_SEED)
sentences = ["apple banana fruit", "banana orange fruit", "orange banana fruit",
"dog cat animal", "cat monkey animal", "monkey dog animal"]
word_sequence = ' '.join(sentences).split()
word_list = list(set(' '.join(sentences).split()))
word_dict = {word: idx for idx, word in enumerate(word_list)}
voc_size = len(word_list)
# Make skip gram of one size window
skip_gram = []
for i in range(1, len(word_sequence) - 1):
target = word_dict[word_sequence[i]]
context = [word_dict[word_sequence[i - 1]], word_dict[word_sequence[i + 1]]]
for w in context:
skip_gram.append([target, w])
model = Word2Vec()
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), **OPTIMIZER_PARAMS)
# Training
for epoch in range(EPOCH_MAX):
input_batch, target_batch = random_batch()
tr_loss = train(model, input_batch, target_batch, loss_func, optimizer)
if (epoch + 1) % EPOCH_LOG == 0:
print(f'Epoch: {epoch + 1}, train_loss = {tr_loss:.6f}')
for i, label in enumerate(word_list):
W, WT = model.parameters()
x, y = W[0][i].item(), W[1][i].item()
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
결과는 이렇게 나오는데 매번 실행할 때마다 결과는 달라지네요. (랜덤시드를 지정해주었는데도 왜 그럴까요..)
결과가 썩 좋아보이지 않지만, 시각화를 위해서 embedding size를 2로 지정한 점과 아주 기본적인 과정만을 다루었기 때문일 것이라고 생각합니다.
'Deep Learning' 카테고리의 다른 글
| [NLP] Vectorization - Bag of Word (0) | 2022.05.06 |
|---|---|
| PyTorch에 발 담가보자 (tensor, reshape, autodiff, gradient descent) (2) | 2022.05.05 |


댓글