[One-hot Vectorization]
자연어 처리를 위해서는 단어 또는 문서를 Neural Network에 입력해주어야 합니다. 그럼 단어 또는 문서를 NN에 어떤 형태로 입력해주어야 할까요? ASCII 코드로 입력해주는 건 어떨까요? a는 0x61, b는 0x62, c는 0x63 이런 식으로요. 괜찮아 보이지만 실제로는 심각한 bias를 초래합니다. 왜냐하면 알파벳 간 거리가 생겨버리기 때문입니다. 실제로 a와 b, a와 c는 동일한 거리로 표현되어야 하지만 아스키코드로 표현하는 순간 a와 b사이의 거리가 a와 c사이의 거리보다 가까워지는 일이 발생합니다. 이렇게 알파벳 간 거리를 모두 동일하게 만들기 위해 사용하는 것이 one-hot vectorization입니다.
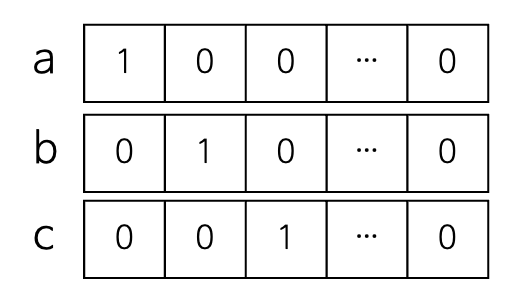
one-hot vector는 vector의 모든 원소 중 하나만 1이고 나머지는 모두 0인 벡터를 의미합니다.
따라서 알파벳들이 다음과 같은 vector로 표현될 수 있습니다.
# Word Representation (단어 표현)
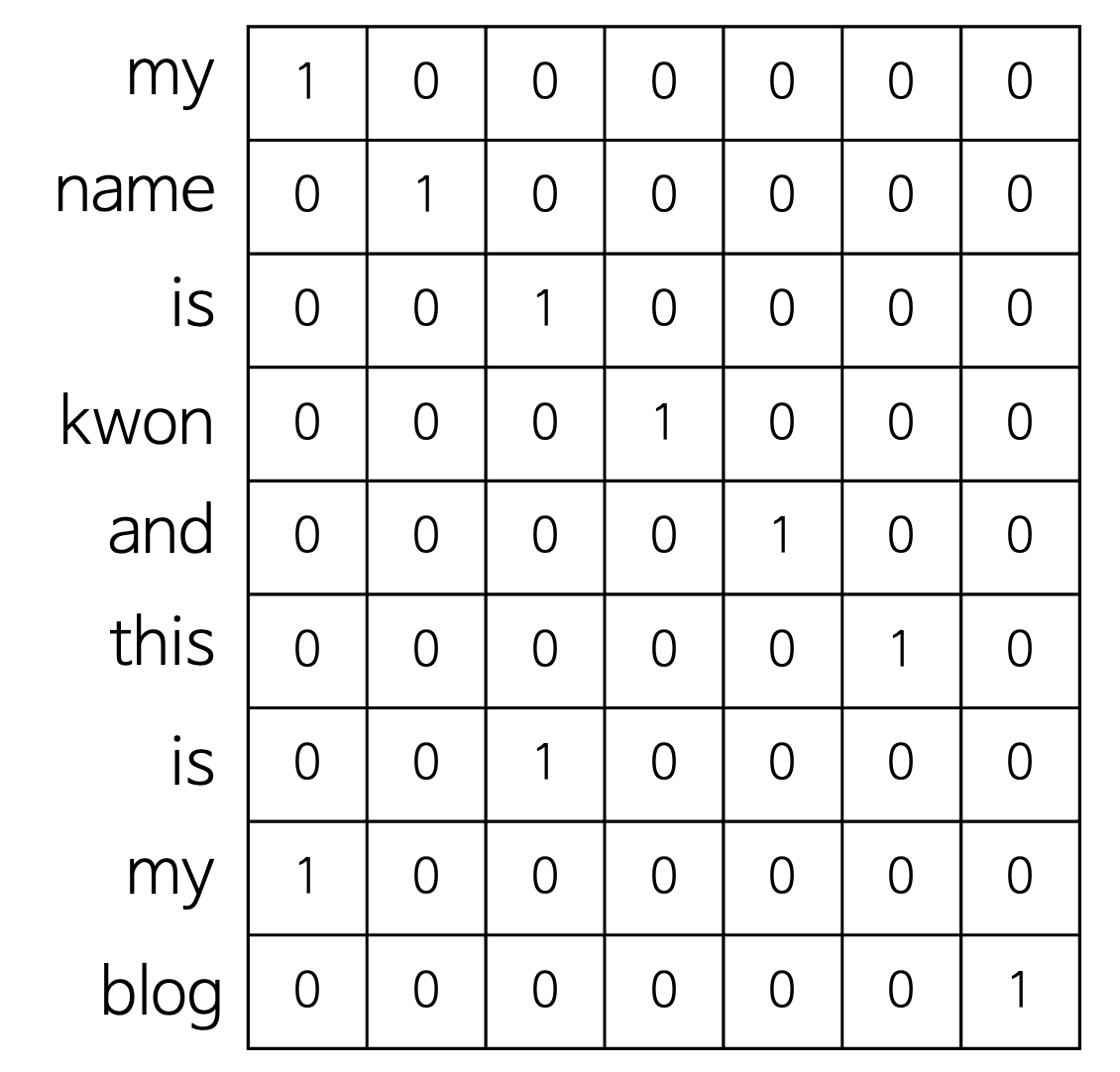
그럼 단어를 one-hot vector로 표현해보겠습니다. 예를 들어, 'My name is Kwon and this is my blog.'에서 7개의 단어를 표현해보겠습니다.

이렇게 단어 하나하나를 one-hot vector로 표현할 수 있습니다. 이렇게 one-hot vector로 단어를 표현하게 되면, 모든 단어 사이의 거리가 같게됩니다.
이렇게 벡터의 한 개의 원소만 non-zero인 표현을 희소 표현(sparse representation)이라고 하는데, 벡터의 한개의 원소만 0이 아닌 값이기 때문에 non-zero element의 비율은 $\frac{1}{|V|}$입니다.($|V|$는 전체 단어의 개수입니다.) 이렇게 표현하는 것은 공간적으로 매우 비효율적입니다. 따라서 우리는 보통 이러한 one-hot vector들을 sparse matrix(희소 행렬)로 표현합니다. sparse matrix는 non-zero 원소의 (인덱스, 값)을 가진 리스트입니다.
위 그림의 dense matrix(밀집 행렬(일반 행렬))을 sparse matrix로 표현하면
my: (0, 1), name: (1, 1), is: (2, 1), kwon: (3, 1), and: (4, 1), this: (5, 1), blog: (6, 1)
이렇게 표현할 수 있겠습니다. 이때 non-zero 원소의 값이 모두 1이라면 값은 생략하고 인덱스만 표현합니다.(일반적으로는 인덱스만 표현합니다.) my: 0, name: 1, is: 2, kwon: 3, and: 4, this: 5, blog: 6
# Document Representation (문서 표현)
단어들을 one-hot vectorization하여 sparse matrix로 표현하였다면 document는 단어들의 집합이기 때문에 자연스럽게 어떻게 표현하는지 알 수 있겠습니다. document는 one-hot vector로 표현된 단어들을 차례대로 붙여서 표현합니다.
이렇게 문서를 벡터들의 연속으로 표현할 수 있습니다. 파이썬은 기본 자료구조로 set과 dictionary를 제공하기 때문에 문서의 단어장(vocabulary)를 쉽게 구현할 수 있습니다.
[ Bag-of-Words Vectorization]
Bag of Words란 단어들의 순서롤 고려하지 않고 문서를 표현하는 방법을 가리키는 말입니다. 단어들을 가방안에 넣어서 표현한다는 의미인데, 가방에 단어들을 넣고 들고다니면 당연히 단어들의 순서가 섞이겠죠! 따라서 단어의 순서를 무시하고 단어의 존재만으로 문서를 벡터로 표현합니다.
이런 맥락에서 one-hot vector의 연속으로 표현된 문서를 압축(projection)한 것이라고 볼 수 있습니다. 단어들의 순서를 무시했기 때문에 문서를 극단적으로 단순화시킨 형태라고 생각할 수 있으며 대부분 classification의 용도로 사용됩니다.
Bag of Words로 표현된 벡터의 원소 값은 hit vector, count vector, tf-idf vector의 3가지 입니다. 하나씩 살펴보겠습니다.
# Hit Vector
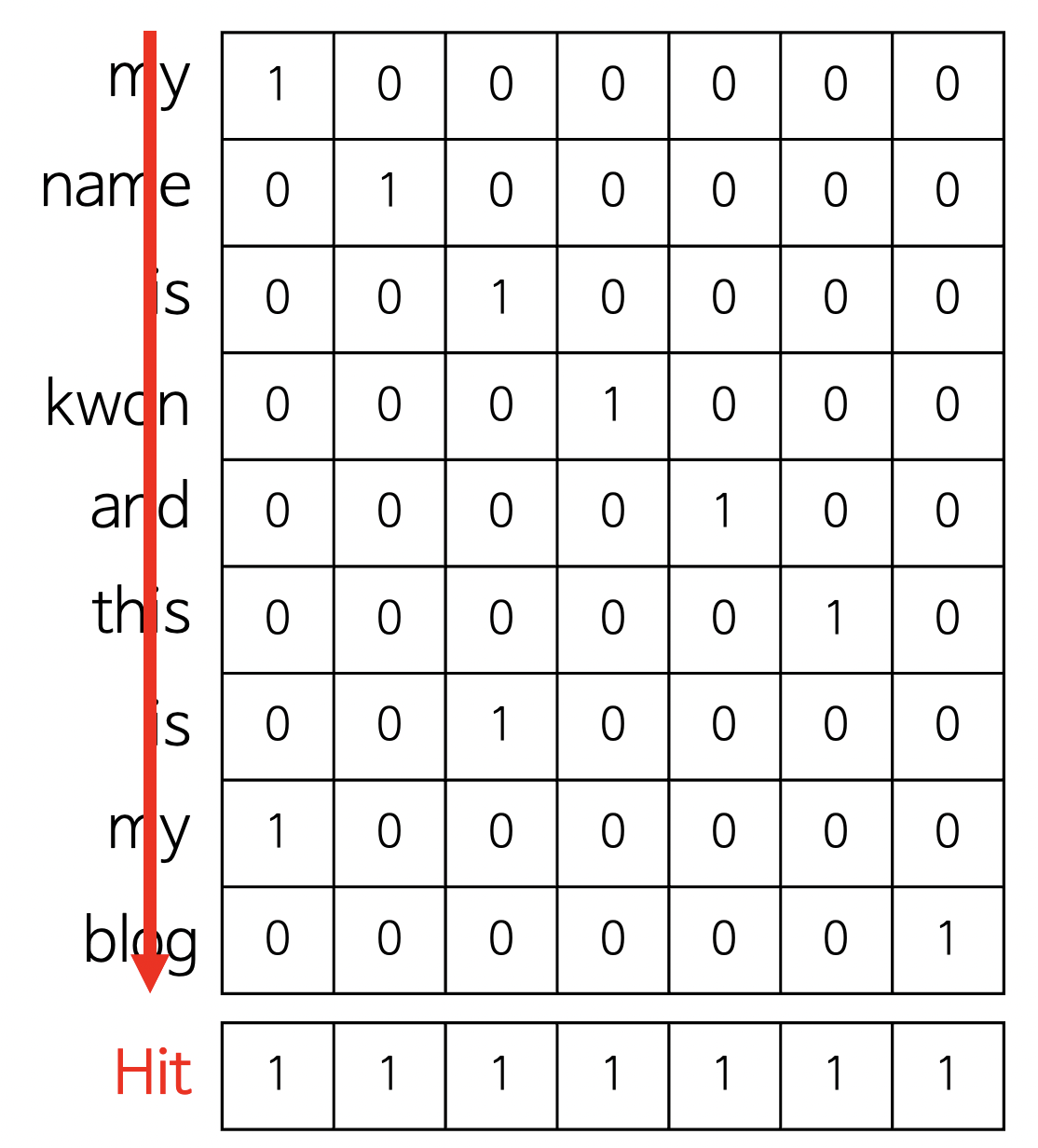
hit vector는 documentation에서 단어의 유무를 표시합니다. 단어가 있으면 1, 없으면 0으로 표현합니다.
# Count Vector

# TF-IDF Vector
Bag of Words 벡터값 중 가장 많이 쓰이고 가장 중요한 vector값입니다.
TF-IDF는 document에서 단어의 빈도와 데이터셋의 모든 document에서 단어의 빈도를 고려한 중요도 값입니다. TF-IDF는 TF값과 IDF값을 곱한 값입니다. 하나씩 살펴보도록 하겠습니다.
TF(Term Frequency)는 document에서 단어의 빈도입니다.
$tf(t, d)=\frac{c(t, d)}{\sum_{w \in d} c(w, d)}$ ($c(t, d)$는 문서 $d$에서 단어 $t$의 횟수)
우리는 이미 단어의 빈도를 나타내는 Count 벡터를 앞에서 사용하였는데 왜 TF값을 다시 정의하여 사용하는 것일까요? 왜냐하면 긴 문서일수록 Count값이 커지기 때문입니다. 따라서 문서의 길이를 고려하여 단어의 빈도를 나타내기 위해 Term Frequency 값을 사용하는 것입니다. 하나의 문서에서 TF값이 클수록 그 문서에서 중요한 단어라고 생각할 수 있겠죠?
하지만, 그 단어가 I, am, is, the, has... 이런 단어라면 어떨까요? 이런 단어들은 모든 문서에서 매우 많이 많이 쓰이는 단어이므로 TF값이 당연히 높을텐데, 이런 단어가 과연 해당 문서에서 중요한 단어라고 볼 수 있을까요? 그렇지 않습니다. 이런 단어들을 거르기 위한 값이 바로 IDF값입니다.
IDF(inverse document frequency)는 dataset의 모든 document에서 단어의 유무 빈도입니다.
$df(t, D)=\frac{\sum_{d \in D} h(t, d)}{|D|}$ ($h(t, d)$는 문서 $d$에서 단어 $t$의 유무, $|D|$는 문서의 전체 개수)
즉, 어떤 단어가 몇 개의 문서에 포함되어 있는지 나타내주는 값이 document frequency이고, idf는 df의 역수를 취한 값으로 많은 문서에서 공통적으로 많이 보이는 단어일수록 idf값은 낮아지게 됩니다.
idf는 여러 가지 버전이 있는데, 일반적으로 많이 쓰이는 것은 $log$를 취한 것입니다. $idf(t, D)=log{\frac{\sum_{d \in D}h(t, d)}{|D|}}$
log를 취해주는 이유는 TF와 IDF의 scale 차이가 커지기 때문에 값의 변화를 줄이기 위해서 입니다. 대부분의 문서에서 사용되는 매우 일반적인 단어의 IDF값은 매우 큰 값을 가집니다. 이를 위해 log로 scale down을 해줍니다.
smooth version은 $idf(t, D)=log{\frac{\sum_{d \in D}h(t, d)+1}{|D|}}+1$입니다. zero division이 되는 경우를 없애기 위해 분모에 1을 더해주었고 그 scale을 같이 맞춰주기 위해 분자에도 1을 더해주었습니다.
즉, TF는 하나의 특정 문서의 특징을 반영해주는 값이고, IDF는 전체 문서들에서 단어가 얼마나 일반적인지를 보여주는 값(일반적인 단어일수록 작은 IDF값)입니다. 따라서 TF와 IDF가 높으면 중요한 단어로 볼 수 있습니다.
이렇게 표현된 Bag-of-words는 단어의 순서가 무시된다는 특징이 있습니다. One-hot vector의 연속으로 표현된 문서 벡터들을 압축(projection)했기 때문에 순서가 무시됩니다. Bag이라는 단어가 쓰이는 이유가 여기 있습니다. (가방안에서는 순서가 모두 뒤섞이기 때문이죠.) 따라서 BOW는 text classification 문제에서는 많이 쓰이지만, 순서가 매우 중요한 문서 번역 등의 문제에서는 사용되기 힘듭니다.
또한 one-hot vector의 연속으로 표현된 문서 벡터들보다 훨씬 덜 sparse한 표현이됩니다. 당연히 projection하였으니까 non-zero 원소의 비율이 훨씬 커지겠죠! 예를 들어 20 Newsgroup 데이터넷에서 각 document가 평균 100개의 단어로 구성되어 있고, 전체 단어의 개수가 약 12만개라면, one-hot vector로 표현된 각 document 벡터에서 non-zero 원소의 비율은 약 1/120000이지만, BOW로 표현된 각 document 벡터에서 non-zero 원소의 비율은 100/120000로 원핫벡터보다 무려 100배 덜 희소한 표현이 됩니다.
자, 이렇게 문서를 벡터로 만들었습니다. 잘 만들어진 벡터들을 이제 신경망에 넣어주어 모델을 학습시켜주면 됩니다. 직접 단어장을 만들고, tf를 구하고 idf를 구하고 vector를 만드는 과정을 손으로 짜보는 과정도 의미가 있겠습니다만, 오늘은 너무 귀찮으니 scikit-learn에서 잘 만들어주신 vectorizer()로 간단하게 벡터를 만들고 classification해보겠습니다. 이후에 손으로 직접 해보는 코드는 추가하도록 하겠습니다.
from sklearn import datasets, feature_extraction, svm, metrics
# Load the 20 newsgroup dataset
remove = ('header', 'footer', 'quotes')
train = datasets.fetch_20newsgroups(subset='train', remove=remove)
test = datasets.fetch_20newsgroups(subset='test', remove=remove)
# Train the vectorizer
vectorizer = feature_extraction.text.TfidfVectorizer() # Try 'CountVectorizer()' (Accuracy: 0.093)
vectorizer.fit(train.data)
# Vectorize the training and test data
train_vectors = vectorizer.transform(train.data)
test_vectors = vectorizer.transform(test.data)
# Train the model
model = svm.SVC()
model.fit(train_vectors, train.target)
# Test the model
predict = model.predict(test_vectors)
accuracy = metrics.balanced_accuracy_score(test.target, predict)
print(f'* Accuracy: {accuracy:.3f}')'Deep Learning' 카테고리의 다른 글
| [NLP] Word Embedding (0) | 2022.05.07 |
|---|---|
| PyTorch에 발 담가보자 (tensor, reshape, autodiff, gradient descent) (2) | 2022.05.05 |


댓글